java常见使用排序方法
- 常用排序工具类java.util.Arrays和java.util.Collections,不过底层都使用了Arrays.sort()
- 使用TreeSet
TreeSet<String> treeSet = new TreeSet<String>(); String[] strs = new String[]{"3","5","6","2"}; for (int i = 0; i < strs.length; i++) { treeSet.add(strs[i]); } //倒序 Iterator iterator = treeSet.descendingIterator(); while(iterator.hasNext()){ System.out.print(iterator.next()+" "); } //升序 Iterator iterator1 = treeSet.iterator(); while(iterator1.hasNext()){ System.out.print(iterator1.next()+" "); }
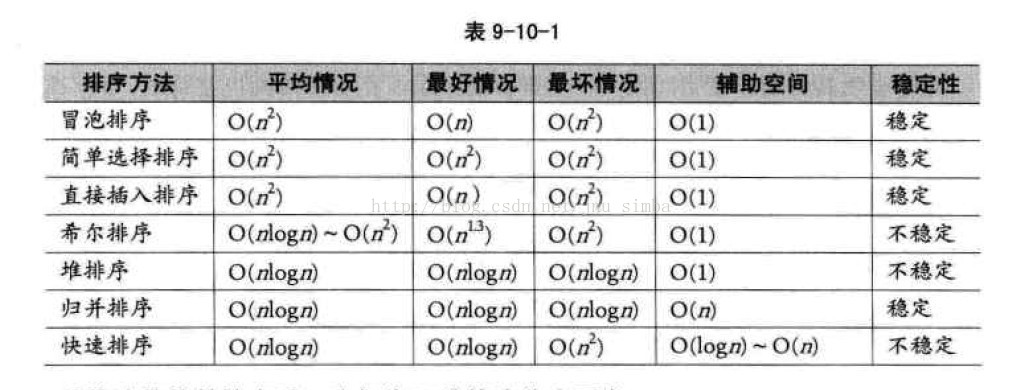
排序算法
一、冒泡排序
基本思想是:两两比较相邻记录的关键字,如果反序则交换
冒泡排序时间复杂度最好的情况为O(n),最坏的情况是O(n^2)
改进思路1:设置标志位,明显如果有一趟没有发生交换(flag = false),说明排序已经完成
改进思路2:记录一轮下来标记的最后位置,下次从头部遍历到这个位置就Ok
二、直接插入排序
将一个记录插入到已经排好序的有序表中, 从而得到一个新的,记录数增1的有序表
时间复杂度也为O(n^2), 比冒泡法和选择排序的性能要更好一些
三、简单选择排序
通过n-i次关键字之间的比较,从n-i+1 个记录中选择关键字最小的记录,并和第i(1<=i<=n)个记录交换之
尽管与冒泡排序同为O(n^2),但简单选择排序的性能要略优于冒泡排序
四、希尔排序
先将整个待排元素序列分割成若干子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序(增量为1)。
其时间复杂度为O(n^3/2),要好于直接插入排序的O(n^2)
五、归并排序
假设初始序列含有n个记录,则可以看成n个有序的子序列,每个子序列的长度为1,然后两两归并,得到(不小于n/2的最小整数)个长度为2或1的有序子序列,再两两归并,…如此重复,直至得到一个长度为n的有序序列为止,这种排序方法称为2路归并排序。 时间复杂度为O(nlogn),空间复杂度为O(n+logn),如果非递归实现归并,则避免了递归时深度为logn的栈空间
空间复杂度为O(n)
六、堆排序
堆是具有下列性质的完全二叉树:每个节点的值都大于或等于其左右孩子节点的值,称为大顶堆;或者每个节点的值都小于或等于其左右孩子节点的值,称为小顶堆。
堆排序就是利用堆进行排序的方法.基本思想是:将待排序的序列构造成一个大顶堆.此时,整个序列的最大值就是堆顶 的根结点.将它移走(其实就是将其与堆数组的末尾元素交换, 此时末尾元素就是最大值),然后将剩余的n-1个序列重新构造成一个堆,这样就会得到n个元素的次大值.如此反复执行,便能得到一个有序序列了。 时间复杂度为 O(nlogn),好于冒泡,简单选择,直接插入的O(n^2)
七、快速排序
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。时间复杂度为O(nlogn)
Arrays.sort()
Arrays.sort()根据不同阈值使用了多种算法,插入排序、快速排序、归并排序
剖析JDK8中Arrays.sort底层原理