设计优化
缓存更新策略

- 低一致性业务建议配置最大内存和淘汰策略的方式使用。
- 高一致性业务可以结合使用超时剔除和主动更新, 这样即使主动更新 出了问题, 也能保证数据过期时间后删除脏数据
缓存穿透
一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去后端系统查找(比如DB)。一些恶意的请求会故意查询不存在的key,请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。
如何避免?
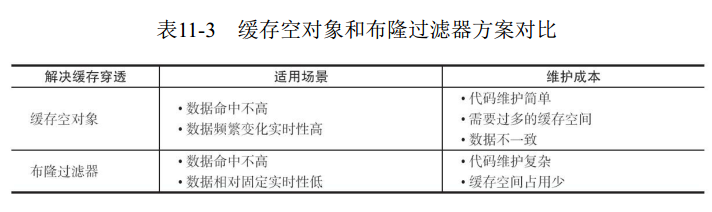
1:对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert了之后清理缓存。
2:布隆过滤器拦截,对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该bitmap过滤。
缓存雪崩
当缓存服务器重启、宕机,会给后端存储系统带来很大压力。导致系统崩溃。
如何避免?
1:保证高可用,做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期
2:依赖隔离组件为后端限流并降级,如缓存调用失败返回默认的数据或者返回请求繁忙等提示(hystrix)
3:提前演练
热点数据重建
大量热点数据在某一个时间段失效,在缓存失效的瞬间, 有大量线程来重建缓存
如何避免?
1:不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
2:在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量,若是分布式的需要分布式锁。 比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
配置统计
配置参数
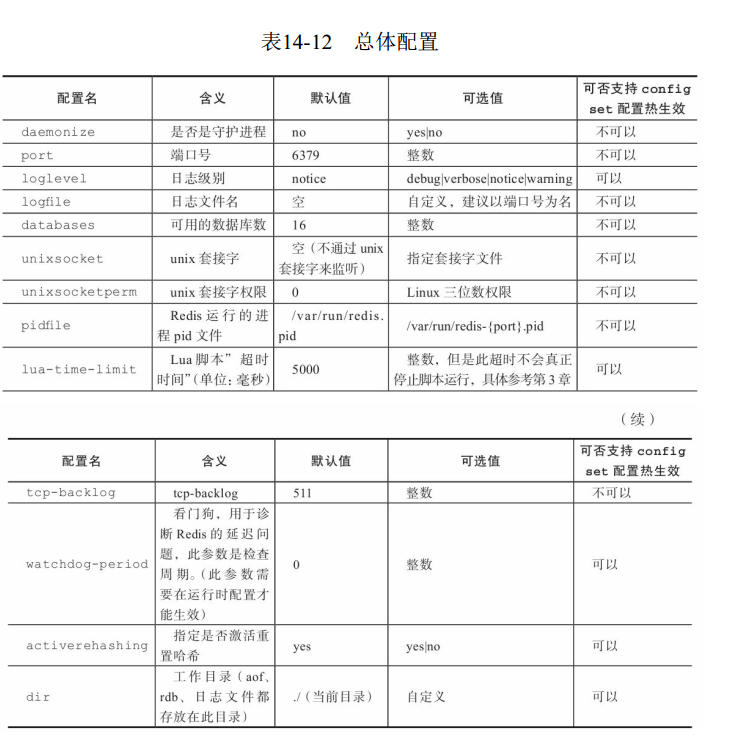
1 总体配置
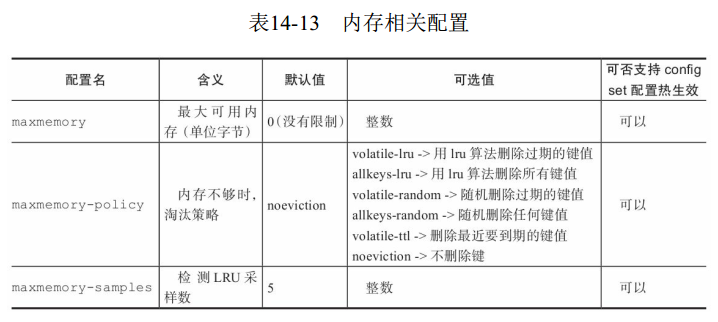
2 最大内存及策略
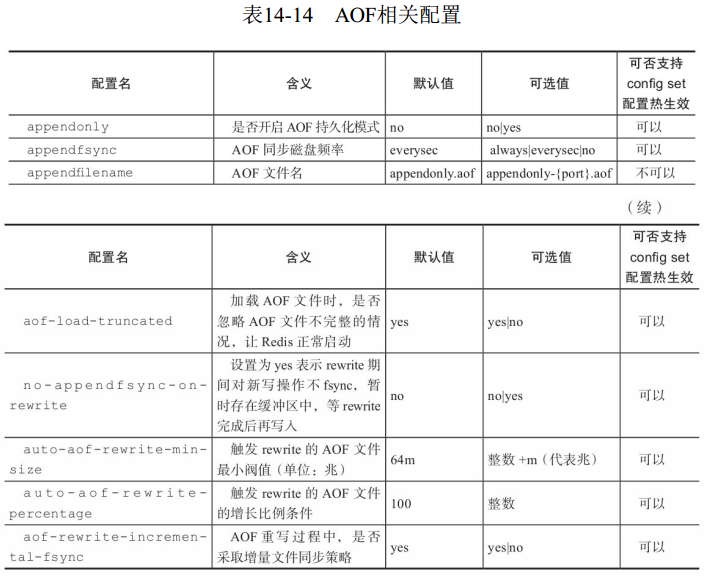
3 AOF相关配置
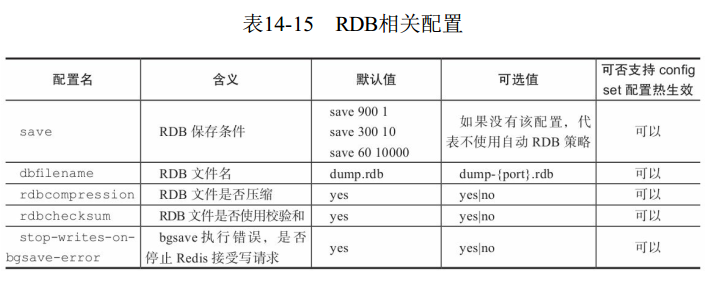
4 RDB相关配置
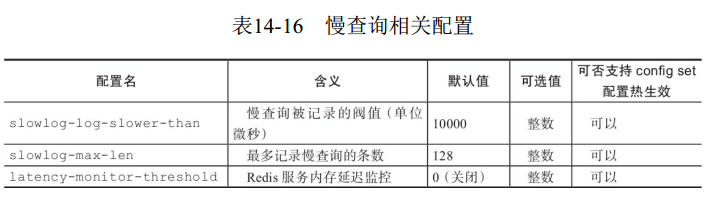
5 慢查询配置
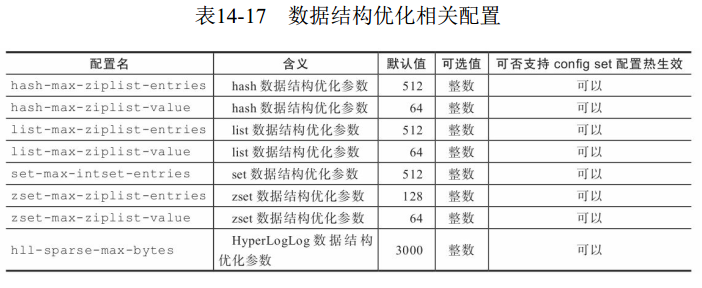
6 数据结构优化配置
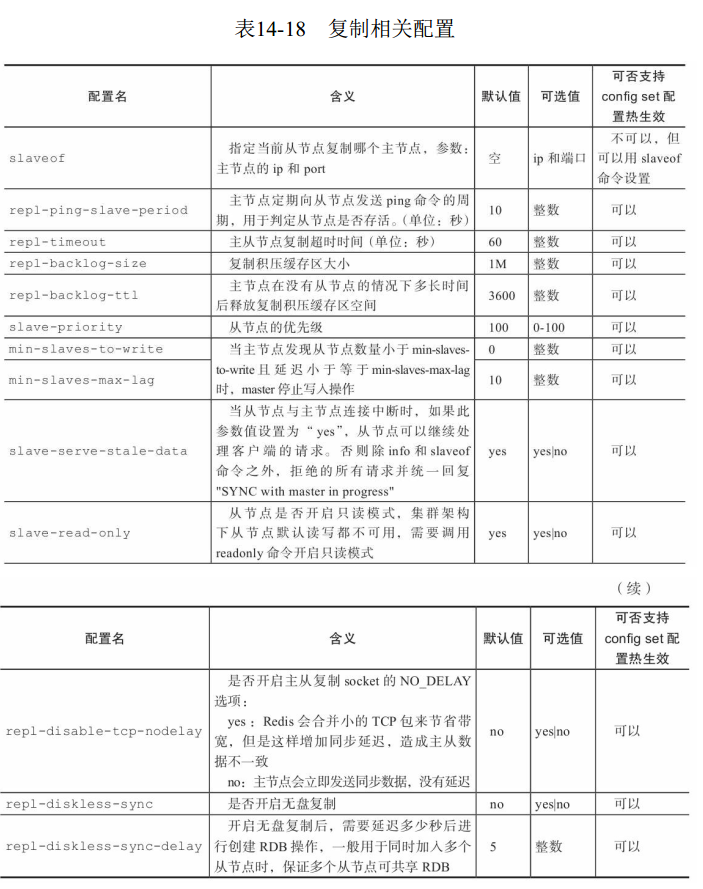
7 复制相关配置
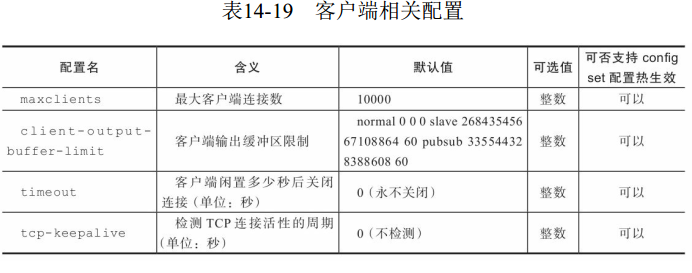
8 客户端相关配置
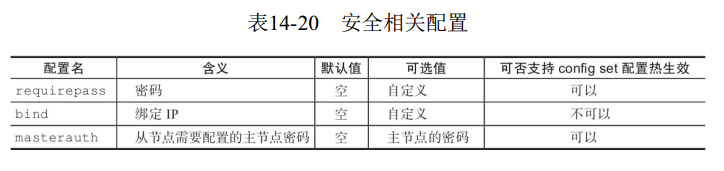
9 安全相关配置
info命令
info 查看部分 info all 查看所有 info <section> 查看指定模块
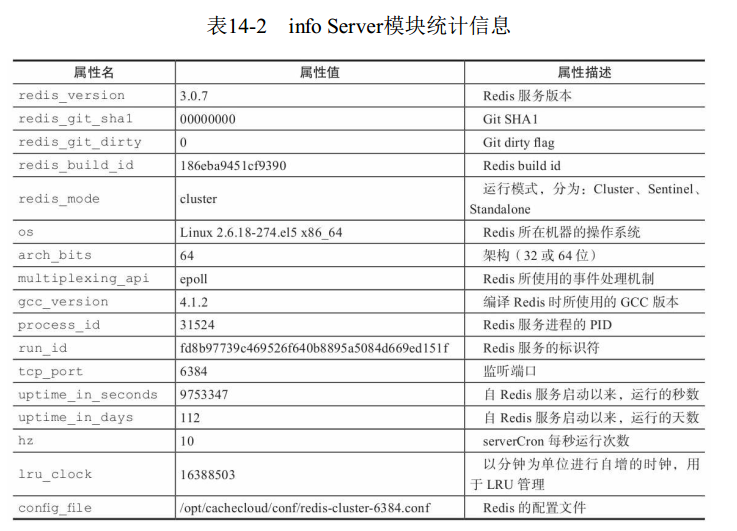
1 info server
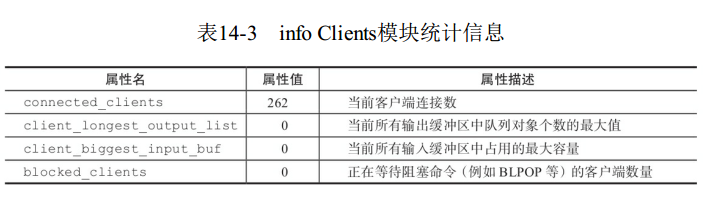
2 info client
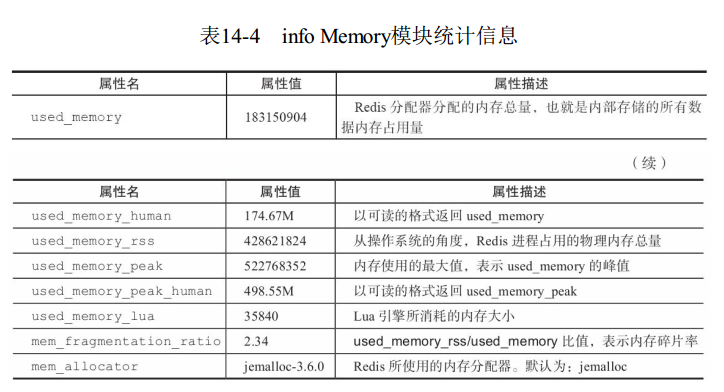
3 info memory
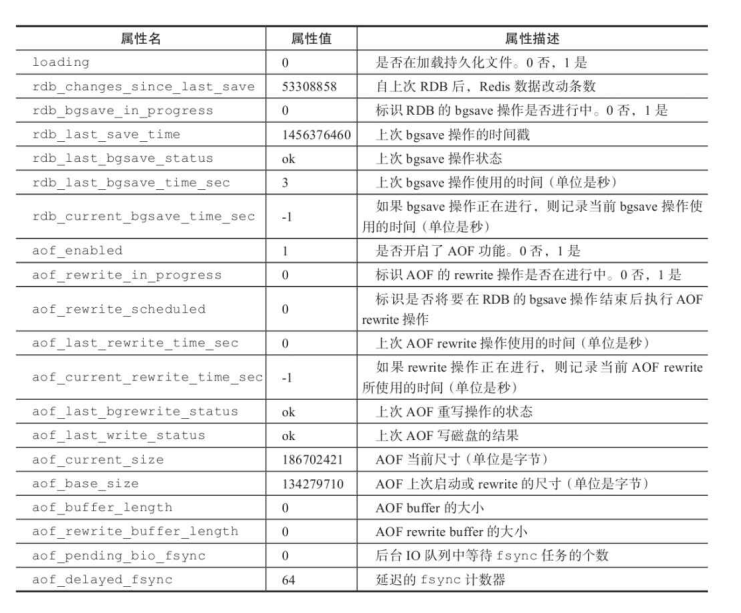
4 info presentce
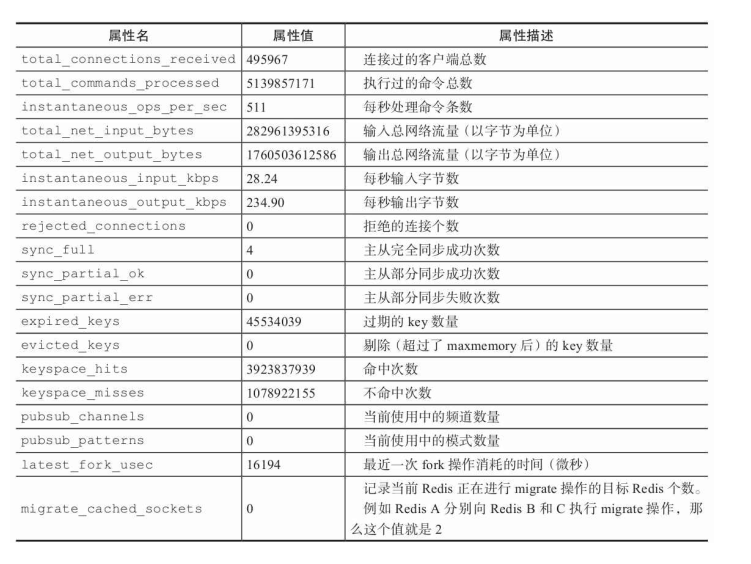
5 info stats
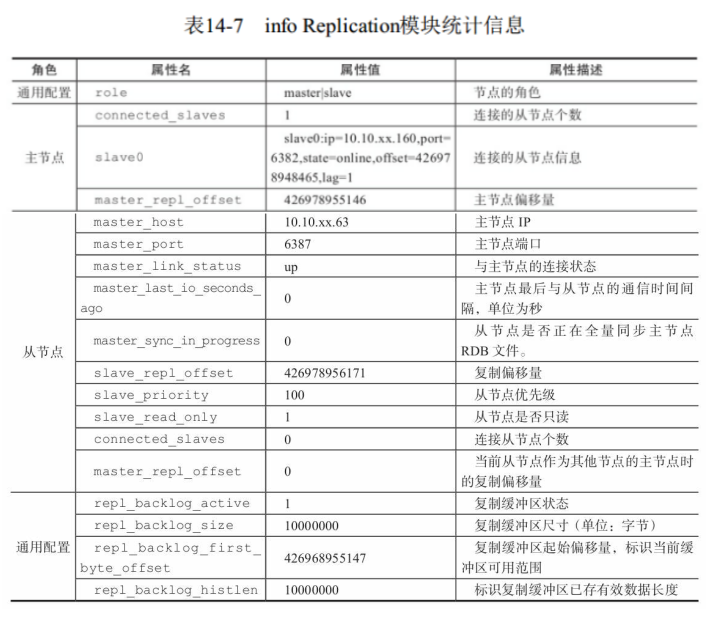
6 info replication
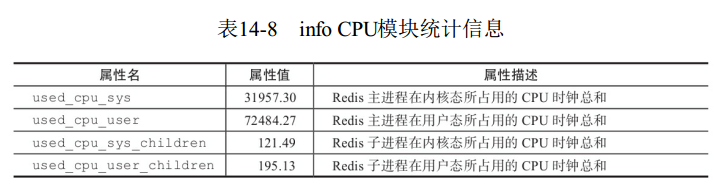
7 info cpu
8 info commandstats

9 info cluster

10 info keyspace
